
Neural Nets and Factor Models

Gu, Kelly, and Xiu (2020) - "Empirical Asset Pricing via Machine Learning" and Chen, Pelger, and Zhu (2019) - "Deep Learning in Asset Pricing" examine various machine learning and neural net algorithms. Both find significant improvements to standard factor models.
Several hidden parameter choices are not directly learned during training but significantly impact model performance. Parameters such as the number of layers, hidden states, and learning rates result in an exponential increase in the number of choices available to the researcher. Furthermore, these researchers present several subclasses of models, as well as combinations of these models (e.g., GANs, LSTMs). The nonlinearity of these models, combined with hidden assumptions, makes them unfalsifiable, making it almost negligent not to have a NN behind your various strategies: there’s only upside. With ChatGPT’s editing capabilities, you can be sure to present a rigorous, incomprehensible approach that is not wrong, so you won’t embarrass yourself even if you don’t really understand what you are doing.
Not only do these approaches capitalize on the AI buzz, but they also exploit a common cognitive bias: people tend to gain unjustified confidence when more inputs are added, even if those inputs don’t improve accuracy. Many instinctively think that 50 firm characteristics, whose effects vary with 10 macro metrics, are better than a 4-factor equity model. Tell that same person that a particular model also measures the interactions of these inputs, the interactions of those interactions, and the interaction of those interactions, and their heads will explode with excitement. As long as Nvidia is booming and people are offering $100 million salaries to top LLM developers, there will be a large demand from those who believe these models are part of the future of everything.

I have worked at places where various neural nets were applied to stock and bond data, and the results were never good. That was well before ChatGPT, but the limitations now are no different from those of today because we haven’t added a billion datapoints in the past decade.
My skeptical intuition comes from two sources.
Number of observations and lack of grammar
AI has gained popularity due to the success of LLMs like ChatGPT 5, which utilizes a neural network with ~1 trillion parameters and is trained on ~30 trillion tokens (1 token equals about 0.75 words). At this scale, neural networks exhibit scaling laws, where performance improves predictably with more data and parameters—often following power-law relationships. Thus, when you ask it to summarize the Thirty Years’ War, it pulls its answer from thousands of essays on the Thirty Years’ War, enabling it to generate informative answers.
Language follows rules like subject-verb agreement, nested structures (e.g., clauses within clauses), and parse trees that resemble hierarchical computations. Transformers—the architecture in modern LLMs—use attention mechanisms to capture long-range dependencies, such as linking a verb to a noun mentioned paragraphs earlier, mimicking how humans process context. With billions of examples, the network implicitly learns semantic grammar, estimating probabilities for coherent continuations more accurately than explicit grammar rules, as it can capture informal patterns.
These syntax/grammar helpers are particularly applicable to other objectives, like proteins and programming code. Languages like Python have strict grammar rules, without irregular verbs, sarcasm, or slang, making them much easier to analyze. Proteins generally have 50% of their structure in alpha helices and beta sheets, and 20k protein domain families (compact, stable, and independently folded region of a protein), and 5k superfamilies. With orders of magnitude fewer tokens, LLMs are very effective in producing correct outputs when their syntax constrains their state space.
There are zero scenarios where the future monthly stock return would be as predictable as finding the last word in the sentence, 'To be, or not to be, that is the ______?' To the extent a pattern exists, competition will reduce the stock market signal-to-noise ratio to a level ChatGPT never has to deal with. This is why stock returns are unlikely to generate patterns revealed by non-linear effects, even if they had one trillion observations, which they don’t (the maximum, if you really reach across the world, is probably 10 million firm-months).
The logic behind the efficient markets hypothesis is why the signal-to-noise ratio between any objective prediction and future returns is low. Perfectly anticipated prices fluctuate randomly due to the law of iterated expectations: if everyone knows the price of AAPL will be $230 tomorrow, it will be $230 today. Thus, for assets without storage costs or dividends, the futures price is determined by the spot price and the interest rate. Equity factors are rare, perhaps ten at max. A factor-factor factor has yet to be identified, making the 5th layer of a stock factor NN an astronomical improbability.
Factors persist not because they are subtle, but because they are so painful, as with low-vol’s lackluster performance in the US this year.
Interaction Effects
For purely linear effects, a neural network with linear activations reduces to a linear model, offering no advantage over standard linear regression. Without significant nonlinear interactions, these models will create spurious patterns due to noise in small sample data, resulting in poorer out-of-sample performance. While NN results are all purported to be out-of-sample—train, validate, test—I doubt that any neural net result has ever been published using its one and only test. As a practical matter, all test results are in-sample; the best out-of-sample test is sub-sample stability.
I have not seen any significant interaction effects between factors. Often, patterns are amplified in smaller stocks, but to the extent that they are significantly different, they exist for the same reason they are overwhelmed by transaction costs.
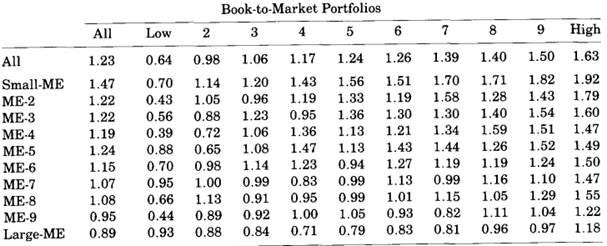
The table above is a cross-tabulation of stock returns from the original 1992 Fama and French paper, showing returns sorted by size and book-to-market. Note the same general monotonic relationship across horizontal and vertical columns. If someone showed me a case where large-cap stocks outperformed low-cap stocks when pre-sorted by something—the opposite of its general pattern—that would indicate a non-linearity that NN would use to generate better performance. Even in that case, it would probably be better to model it directly via an explicit interaction formula or using a 2-D grid interpolation.
Regarding the time variation factors, such as credit spreads and the VIX, I am skeptical because macroeconomists have still been unable to predict recessions despite approximately 80 years of trying. The cliché ‘history shows’ is apt here, as it is much more likely a researcher will find a pattern that worked in past recessions but completely miss the next one, generating false positives in the meantime. The fact that these macro factors are multiplied by firm-specific factors (and these products by each other) merely amplifies the probability of picking up spurious correlations, as it becomes more difficult to discern the absurd cross-correlations within these models.
The fat tails and asymmetric distributions of many of these ratios obviously require normalization of firm characteristics. This is especially true when throwing 46 or 94 characteristics into a regression, as there will be many highly correlated inputs that generate spurious significance because they are picking up monotonic nonlinearities via correlations between firm characteristics (eg, the nonlinear functions log(x) and 1/x are nonlinear and monotonic, x^2 is nonlinear and non-monotonic). Xiu et al. list short-term reversal, 12m momentum, momentum change, industry momentum, recent max return, and long-term reversal as their top factors, and these are all highly correlated. I suspect their models are exaggerating the significance of these factors because their correlation with each other is significantly greater than with future returns.
I do not have a dog in this, but I suspect neural net/machine learning algorithms will be like ESG scores a decade ago. They have marketing value.